
Featured on the 2023 TreeHacks Devpost blog
With backgrounds from all over the country, we found that the largest uniting factor for our team was our shared role as students. Soon into the project ideation phase, we discovered that we were interested in Education for its necessity in our lives (and pretty much everyone else's) and New Frontiers for its seemingly endless potential in all applications!
Even with our general goals determined, we found quickly that most education related project ideas were all specific to individuals (not the larger population that we wanted to help). With that realization, MindScape was born as a flexible AI-powered educational tool, built to serve our user in any learning goals they have.
Faruq Yusuff, Aayush Garg, Michelle Feng and I built this February 17-19, 2023 at TreeHacks. TreeHacks is one of the largest hackathons in the world with more than 1,700 hackers involved in the three day competition at Stanford's engineering quad in Palo Alto, California.
Backend source code for our project is available here and frontend source code is here on GitHub.
Using insights from a screening on learning type, MindScape tailors learning experienes for users based on videos or course notes that they may have trouble comprehending on their own. Experiences can vary to have a focus on visual, auditory, and social learners. Additionally, we recognize that very few people are entirely one type of learner, and as a result have afforded users the opportunity to test out other study types to judge whether they like them!
All of our team was well-versed in fullstack development, but with different frameworks, so part of our process was figuring out how to puzzle our skills together.
This is a picture of our sketches from night 1. From left-to-right, we wrote down what stack we wanted to work with, what API endpoints would be needed, and created general flows for our user experience.

MindScape came out of thoughtful delegation of tasks. Each team member had concrete goals within frontend, backend, and "exploration" (what we're calling the development in AI/NLP-uses of our learning plans). All of these tasks had room for their member to use their own autonomy and creativity. We all gained new technical skills and had a good time!
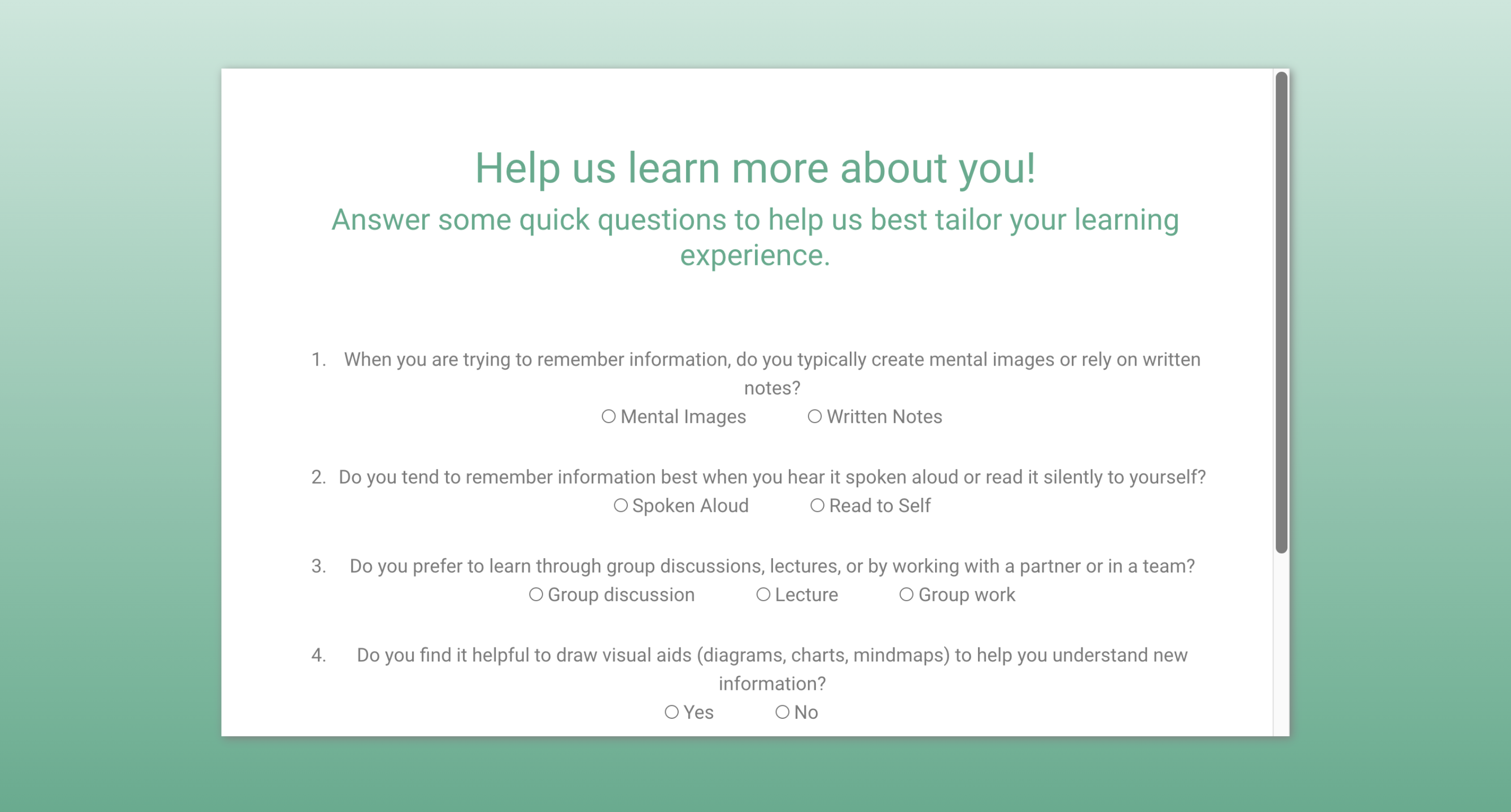
A general flow of control begins with a user entering their username. The system then verifies whether or not this user has been a prior MindScape user. If so, their learning style has been recommended to them before and the same one is recommended again during this session. Otherwise, the user is prompted to take a quiz to assess their optimal learning style.
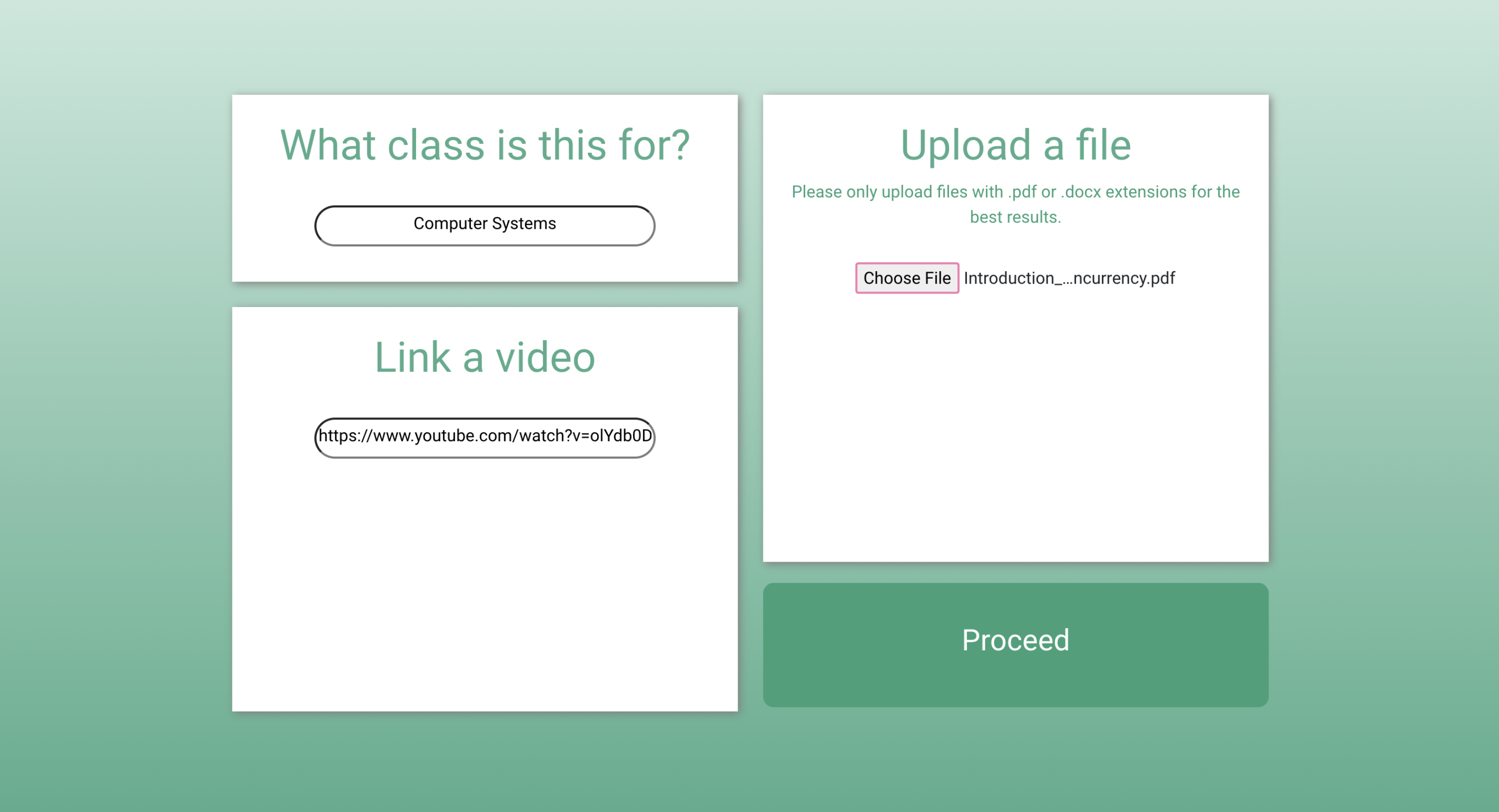
Resources are needed for the next part of the project after the learning style quiz is completed. Resources include a link to a video or a pdf/doc/docx file containing the student's class notes.
Users are then shown their recommended learning style highlighted in green, followed by two other possible options. If they are unhappy with the recommended learning arrangement, it is possible to switch learning modes at anytime to fit their needs.

Depending on the learning style selected, MindScape then branches out to tailor the learning experience to the student. Below we enumerate and explain the possible scenarios:
Visual Learner: A mindmap is built on the backend and displayed to the user. It is represented as an n-ary tree such that each child node relates to its parent.

The largest challenge for this section stemmed from representing OpenAI json output in a visual tree. To combat this abstract idea, we leveraged the graphviz open source graph visualization software. The json was then treated as a nested dictionary of n dictionaries pertaining to the number of children for tree traversal purposes.
Social Learner: OpenAI proved crucial here as well, with its API being utilized for our chatbot. The chatbot backend is enabled with text embeddings, which measure the relatedness of text strings. Other common use cases for text embeddings are found on the OpenAI website. For our purposes, the relatedness of a user's question string and text within their inputs, recommendations, clustering, search, and classification are each used to varying degrees. Embeddings are vectors of differing floating point numbers where the Euclidean distance between vectors measures their respective relatedness. Behind the scenes, this is done for our text inputs and user chatbot inputs. A smaller Euclidean distance between two vectors (ie: text input from sentence #24 and chatbot input) indicates high relatedness, while a larger distance tends to preclude highly related inputs. The way this looks in our project is that a user opens a chatbot session and specifies a certain request.

OpenAI then conducts its text embedding process to find a relevant section of text to respond to the question or comment. Disjoint of this, OpenAI search is used to generate links to related materials. These links will appear for the user regardless of if their query is answerable in the provided materials. As mentioned, one challenge with this workflow is that sometimes the provided text materials do not contain an answer to a user chatbot query. If this is the case, the bot is programmed to alert the user of this before then using GPT3 to offer some details. The related links will appear below that as per usual. The chatbot frontend was developed using react-chatbot-kit and resembles a text conversation on your mobile phone of choice. The sleek, modern design will appeal to users used to the same format on their mobile devices.
The user can then learn using different materials in their same "class" or add a new class with its own separate set of materials. After the learning session, they can change their learning preferences if desired or stick with it if the recommendation seemed apt for them.
Working with new mediums: Our project definition meant that we were working with technology that would potentially connect through users through all senses. Creating different technological components to meet the needs of differently wired learning individuals is difficult to wrestle with at times. We found that envisioning yourself in the shoes of a MindScape user helps to gain perspective with respect to which features should be strongly prioritized.
Authentication formats: Our initial flows had a login/signup capability. Despite this being a classic feature, it ended up taking a decent amount of time on the backend. Instead of sacrificing more time towards our core features, we decided to modify our project to store user IDs locally (which would give them access to their past classes and learning data). This modification showed us that traditional features to projects aren't always necessary. In fact, our solution gives users more easy access to their MindScape platforms and bypasses unnecessary logistical headaches.
This is only the beginning for MindScape, and all of us hope to take the lessons we've learned at TreeHacks this weekend to our future endeavors, whether they be related to MindScape or other impactful projects!
Possible avenues for improvement revolve around increased fluidity and further functionality. Below are some examples to consider: